网站首页 科技 > 正文
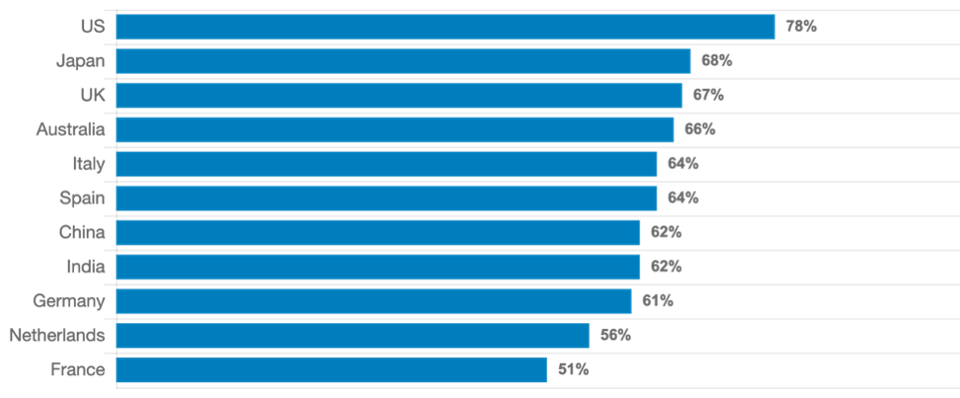
几乎每一位与我交谈过的首席信息官都大胆宣称,他们的企业是“数据驱动型企业”。然而,毕马威最近进行的全球CEO前景调查却大相径庭:全球67%的CEO(美国这一数字跃升至78%)表示,他们忽略了由他们提供的CIO/数据驱动的分析预测模型IT团队,因为这与他们自己的经验相矛盾;他们根据直觉做出了重要的商业决策。
一个无视数据驱动的见解,追随直觉的CEO。
虽然结果有些令人震惊,但很容易解释。首先,虽然企业产生的数据量是足够的,但数据仍然分散在业务单元、领域、平台和实现(如云和私有数据中心)之间。根据Forrester的数据,高达73%的公司数据没有用于分析和洞察。难怪CEO的模型只用了总数据的27%就取得了可怕的结果!其次,大多数当前的预测模型只使用历史数据,而不是流式(实时)数据。这两个重要因素导致预测精度低。如果首席执行官不信任该模式,他们就无法做出决策,因为他们业务的成败取决于他们做出的决策。
更多的数据可以带来更好的预测。
IT运营虽然让其他企业的AI计划得以顺利运行,但实施AI来改善自身运营却很慢。一个原因是以上数据比较分散。当您向AI/ML模型提供部分数据时,您将只能获得企业的部分视图。另一个主要原因是,大多数AI/ML实现都是为了创新,通常由BU资助。传统上,企业将IT视为成本中心,因此不愿意花钱使用AI来改善运营。然而,随着大量数据和当前的大流行产生了更多断开的远程数据,当这种感觉开始压倒运营团队时,它发生了变化。IT团队正在到达一个临界点,有太多的数据需要处理,这是AI的理想解决方案。这是AI和ML的最佳选择。基于大量数据的人工智能正在蓬勃发展。事实上,反馈给AI算法的数据越多,模型就越好。
传统上,it运营团队多年来一直在监控IT基础架构监控(ITIM)和网络性能监控与诊断(NPMD)层。在过去十年中,应用程序性能管理(APM)帮助提高了每个应用程序的可见性。然而,即使所有这些系统都显示它们正常工作,客户仍然会根据位置、连接类型(移动/互联网)、使用的缓存类型/CDN提供商等遇到问题。当现代应用程序及其组件被加载到客户视图中时,它们的复杂性将变得非常复杂。数字体验监控(DEM)的概念获得了可见性,可以监控、分析和优化客户体验。然而,它们更像是监控工具,而不是诊断工具。
ai ops(it运营中的人工智能)解决方案可以帮助解决这个问题。一个好的AIOps解决方案应该能够从多个来源获得数据,消除噪声,关联事件序列,并基于历史数据和实时数据的组合产生可行的见解。
数据采集
可以说这是最重要的一步。不仅需要将历史数据反馈给AI进行模型创建,还需要将实时数据反馈给AI进行模型推理和更新。像过去一样收集日志或SNMP并不能提供企业的全面情况。收集尽可能多的信息,包括事件、日志、时间序列数据、应用程序数据、性能数据、利用率数据等。新的基于事件的模式转变为发布/订阅或基于事件的消息传递。尽管这些消息非常重要,但它们对于收集实时数据以提供企业的完整视图并做出准确预测来说是绝对必要的。大多数基于云的系统,无论是基于容器的还是基于虚拟机的,都是通过API提供大量的信息。
收集结构化、半结构化和非结构化数据。尽管现有的BI和分析系统在处理非结构化数据时遇到了困难,但AI仍然喜欢它。它可以解析几乎所有内容,包括音频、视频、文本文件、图像、配置文件、文档、PDF文件等等。
最后,大多数团队忘记了带配置记录、变更管理系统、CMBD等。作为等式的一部分。这对于敏捷团队来说尤其重要,他们有时会每天推进多个发布周期。除非信息技术运营团队意识到最近的变化,否则他们会浪费大量时间来找出问题的根本原因。
数据质量和数据获取。
AI存在数据质量问题。在创建AI/ML模型时,“填埋,填埋”是非常正确的。你的算法有多好,你的数据科学家有多好,都无关紧要。如果你没有提供足够的质量数据,你将一无所获。当企业收集大量数据时,仍然是不完整、不正确和/或不一致的。您还需要收集相邻和相关的数据。你可能会认为它们无关紧要,但你会惊讶于人工智能可以用看似无关的数据找到什么。例如,当美国宇航局的卫星发生故障时,IBM AI工程师和美国宇航局的科学家发现了一种利用太阳光计算紫外线强度的方法,准确率高达98%。我最近写了一篇关于这个的文章,可以在这里看到。
如果你和数据科学家交谈,他们会告诉你他们花了多少时间准备数据。他们花费高达80%的时间准备数据,而不是分析数据或创建和微调模型。
数据的分类和标记。
需要对数据进行正确的分类、归类和标注,以便AI/ML可以从中学习。对于监督学习模型尤其如此。在训练、验证和调整模型之前,这是。
重要的一步。标签的准确性和质量是最重要的两件事。准确性衡量的是标签与真实情况之间的接近程度,或与您的企业事实和/或实际条件匹配的程度。质量与用于模型的整个数据集的标注准确性有关。当您结合使用自动,外包和内部标签工作时,尤其如此。所有组都会在整个数据集中一致地标记吗?数据清理
如果使用偏差数据训练AI模型,则无疑会产生偏差模型。我写了一篇有关如何避免这种情况并使您的数据失偏的文章。原始数据可能包含隐性偏见信息,例如种族,性别,出身,政治,社会或其他意识形态偏见。消除它们的唯一方法是分析不平等并在创建模型之前对其进行修复。如果不从数据中消除歧视性做法,该模型将倾向于产生有偏见的结果。
仅当数据来自经验证,权威,经过验证和可靠的来源时,才应包括在内。来自不可靠来源的数据应该完全消除,或者在输入模型时应给予较低的置信度。另外,通过控制分类精度,可以以最小的增量成本来大大减少辨别力。这种数据预处理优化应集中在控制区分,限制数据集中的失真和保留实用程序上。
资料储存库
考虑到数据的数量,速度和种类,用于数据存储和数据管理的传统现场解决方案不适用于数字本机解决方案。许多公司已采用数据湖解决方案来解决此问题。尽管单个集中的数据源可以提供帮助,但需要对其进行适当的安全保护,管理和定期更新。它应该能够无缝处理结构化和非结构化数据。
结论
人工智能需要大量数据。正如我最喜欢的《短路》中的角色Johnny V(基于AI的机器人)说:“我需要更多的输入……”。如果您的高管要基于此做出重大的企业决策,请确保为AI提供正确数量和质量的数据。如果没有,他们将忽略您的模型输出/建议并做出自己的决定,从而最大程度地降低您的价值,并最终使您获得数字化和改善业务所需的资金。
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。 标签:ITAI免责声明: 本文由用户上传,如有侵权请联系删除!
- 上一篇: 人工智能非常耗能——新硬件可能会抑制它的胃口
- 下一篇: OpenAI——加速人工智能
猜你喜欢:
- 2023-07-05 酸梅四物饮怎么做(酸梅饮料怎么做的)
- 2023-07-05 英雄联盟手游光明哨兵活动任务怎么做(英雄联盟手游光明哨兵活动任务怎么做视频)
- 2023-07-04 叠杯子教程玩法(叠杯子教程玩法6个)
- 2023-07-04 微信怎么直接向手机号转账(微信怎么直接向手机号转账了)
- 2023-07-04 如何学习蹲踞式跳远:[1]助跑与起跳(蹲踞式跳远助跑的动作要领)
- 2023-07-04 360安全浏览器和极速浏览器哪个好(360安全浏览器和360极速浏览器哪个更好)
- 2023-07-04 mac地址怎么查(mac地址怎么查命令)
- 2023-07-04 怎么在去哪儿网上订酒店?(网上订酒店在哪里)
最新文章:
- 2023-07-05 易语言做qq强制聊天软件(Qq强制聊天软件)
- 2023-07-05 新倩女幽魂端游一条龙任务之大盗宝藏副本玩法(倩女大盗宝藏攻略)
- 2023-07-05 CDR怎么填充多种颜色渐变(cdr渐变色填充)
- 2023-07-05 页边距怎么设置(页边距怎么设置在哪里Word)
- 2023-07-05 win10兼容模式怎么设置在哪(win10兼容模式怎么设置在哪里)
- 2023-07-05 网易126邮箱如何设置黑名单?(网易邮箱126解除黑名单)
- 2023-07-05 英雄联盟手游凯南怎么出装(英雄联盟手游凯南怎么出装备)
- 2023-07-05 点点赚怎么答卷赚钱攻略(赚点答题技巧)
- 2023-07-05 自己做电脑系统最简单的方法!(自己做电脑系统最简单的方法是什么)
- 2023-07-05 快手放电影怎么放啊(快手放电影怎么放)
- 2023-07-05 QQ如何更换密保手机(qq如何更换密保手机号申诉不记得手机号了)
- 2023-07-05 win10默认安装路径在哪里设置如何修改安装路径(windows10修改默认安装路径)
- 2023-07-05 万网域名证书在哪里?怎么打印万网域名证书?(如何打印域名证书)
- 2023-07-05 原神神里绫人的圣遗物怎么获得(原神神里绫华平民圣遗物)
- 2023-07-05 微信转账0.01恶搞步骤(微信转账0.01恶搞文字)
- 2023-07-05 电子书营销技巧(电子书营销技巧与方法)